204700PINA:从单个RGB-D视频序列中学习个性化的隐式神经化身0董子健�1 郭晨�1 宋杰†1 陈旭1,2 安德烈亚斯∙盖格2,3 奥特马∙希利格斯101 ETH Z¨urich 2 Max Planck Institute for Intelligent ...
”RGB-D视频序列 姿势无关蒙皮场学习 动画化未见姿势“ 的搜索结果
15893用于人体模型的结构化局部辐射场郑泽荣1,黄汉2,俞涛1,张宏文1,郭艳东2,刘业斌11清华大学自动化系2OPPO研究院摘要从RGB视频中创建一个可动画化的穿着衣服的人体化身是非常具有挑战性的,特别是由于运动建模...
RGB-D传感器和3D点云的研究不断发展,在视障者避障方面取得了新进展。 然而,由于设计健壮和实时算法的困难,它仍然是一个具有挑战性的问题。 在本文中,我们专注于场景分割和标记。 由于人造室内场景包含许多平面...
用于3D服装动画的自动深度蒙皮和姿势空间变形0Hugo Bertiche 1 , 2 , Meysam Madadi 1 , 2 , Emilio Tylson 1 和 Sergio Escalera 1 , 201 西班牙巴塞罗那大学和2 计算机视觉中心0hugo ...
我们的两步框架采用身体像素到表面的对应图(即,IUV图)作为代理表示,然后执行参数化的人体姿势和形状的估计具体来说,给定估计的IUV图,我们开发了一个深度神经网络,优化3D身体重建损失,并进一步集成渲
niche}@eng.ox.ac.uk摘要在这项工作中,我们提出了第一个基于端到端深度学习的方法,该方法可以从RGB图像中预测3D手部形状和姿势。我们的网络由深度卷积编码器和基于固定模型的解码器的级联给定输入图像和从独立CNN...
本文首先介绍了相关的RGB-D数据集,然后在该数据集中提取部分图片组成训练、验证和测试集。然后对这些选取的图片进行预处理,包括去除RGB-D图片的背景,和补齐深度(D)图片的深度信息。利用深度信息图和转换到不同...
+v:mala2255获取更多论文AvatarCap:可动画化的化身条件单目人体体积捕获Zhe Li,Zerong Zheng,Hongwen Zhang,Chaonan Ji,Yebin Liu清华大学自动化系抽象的。 为了解决单目人体体积捕获中部分观察引起的不适定...
给定捕获可变形对象的多个休闲视频,BANMo重建可动画化的3D模型,包括隐式规范3D形状、外观、蒙皮权重和时变关节,而无需预定义的形状模板或注册的相机。左:输入视频;中间:规范空间中的3D形状、骨骼和蒙皮权重...
* Both authors contributed equally to the paper1philgras.github.io/neural_head_avatars/neural_head_avatars.html186530来自单目RGB视频的神经头像0Philip-William Grassal 1 � Malte Prinzler 1 � ...
摘要当前用于学习逼真且可动画化的3D穿着化身的方法需要具有仔细控制的用户姿势的3D扫描或2D图像。相比之下,我们的目标是只从处于非约束姿势的人的2D图像中学习化身给定一组图像,我们的方法估计一个详细的3D表面从...
今天学习了骨骼动画,终于让偶的模型动起来啦!!! 一.简介 说到动画,其实本人又想起了最早开始写小游戏的时候从网上找的那些关键帧素材,设置一个定时器,或者根据游戏循环,不断切换图片,就形成了动态的效果...
原文:Monocular Human Pose Estimation: A Survey of Deep Learning-based Methods摘要:基于视觉的单目人体姿态估计是计算...
11708Neural-GIF:用于服装Garvita Tiwari1,2 Nikolaos Sarafianos3 Tony Tung3 Gerard Pons-Moll1,21... 我们提出了神经广义内隐函数(Neural-GIF),以动画的人在服装作为一个功能身体姿势。Neural-GIF直接从扫描中
1ARCH:可动画重建的衣服人类曾煌1,2刘伟,徐元璐1,Christoph Lassner1,Hao Li2,Tony Tung11 FacebookReality Labs,Sausalito,USA2美国南加州大学[email protected],[email protected],[email protected],hao@...
1神经关节辐射场野口敦宏1小孙2林志颖2原田达也1,31东京大学2微软亚洲研究院3理研摘要我们提出了神经关节辐射场(NARF),一种新的可变形的三维表示从图像中学习的虽然3D隐式表示的最新进展已经使得学习复杂对象的...
我们提出的HumanNeRF利用实时高效的一般动态辐射场生成和神经混合,为动态人类提供高质量的自由视点视频合成。我们的方法只将稀疏图像作为输入,并在大型人类数据集上使用预先训练的网络。然后,我们可以有效地从一...
弗里曼·拉胡尔·苏克坦卡尔·克里斯蒂安·斯明基塞斯库Google Research{hongyixu,egbazavan,andreiz,wfreeman,sukthankar,sminchisescu}@ google.com摘要我们在一个完全可训练的、模块化的深度学习框架内提出...
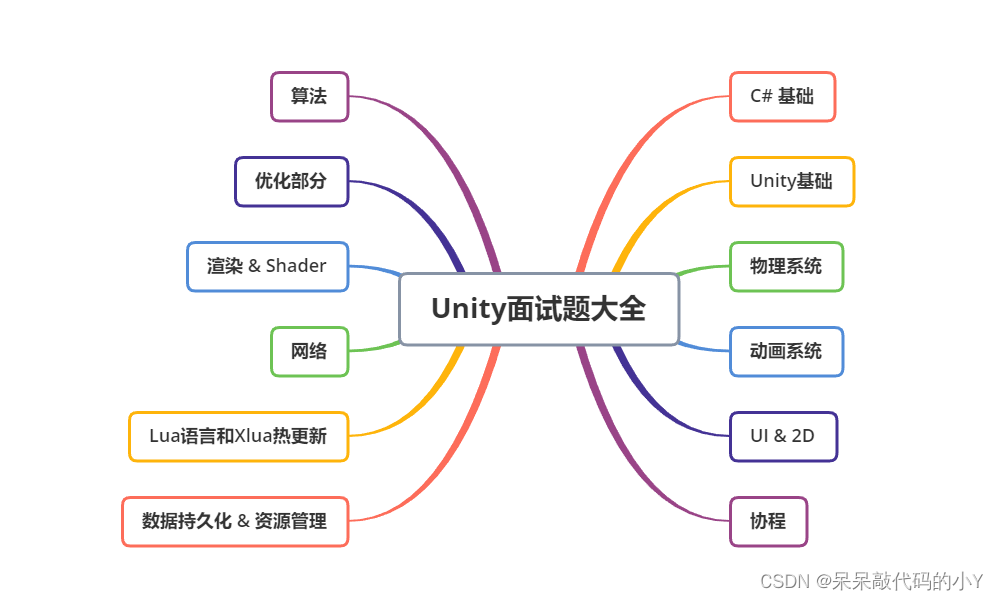
Unity学习知识和链接汇总-持续更新
11097CPF:学习接触势场来模拟手-物交互Lixin Yang1,2 Xinyu Zhan1 Kailin Li1 Wenqiang Xu1,2 Jiefeng Li1 Cewu Lu1,2,†1上海交通大学2上海启智学院{siriusyang,kelvin34501,kailinli,vinjohn,ljf likit,...
56050SelfRecon:从单目视频中重建您的数字化人物形象0Boyi Jiang 1,2 Yang Hong 1 Hujun Bao 3 Juyong Zhang 1*01中国科学技术大学2图像导数公司3浙江大学0摘要0我们提出了SelfRecon,一种结合隐式和...
2 Matthias Nießner 1 Angela Dai 101 慕尼黑工业大学 2 图宾根智能系统研究所0t 1 t 20t N0s0单目深度序列0潜在代码优化0形状0形状MLP0姿势重建0p N0姿势MLP0t 1 t 2 t N0p 2 p 10图1:...
多视角视频0第1帧0第100帧0第200帧0输出:可动的人体模型0重塑的几何形状 合成的图像0图1:给定一个表演者的多视角视频,我们的方法重建了一个可动的人体模型,可用于新视角合成和新姿势下的3D形状生成。...
我们提出了基于野外视频数据的深度网络的多帧自监督训练,用于联合学习人脸模型和3D人脸重建。我们的方法成功地解开面部形状,外观,表情和场景照明。摘要基于单目图像的人脸三维重建是计算机视觉领域的一个
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处图1.。顶部:D3DFACS数据集的样本。中部:仅模型注册。底部:仅使用模型进行表情转移到Beeler等人[2011]的主题。3D面部建模领域存在着高端和低端方法之间的...
13D Safari:学习从“野外”图像中估计斑马的姿势、形状和纹理SilviaZuffi 1AngjooKanazawa 2TanyaBerger-Wolf 3Michael J. 黑41IMATI-CNR,米兰,意大利,2加州大学伯克利分校3伊利诺伊大学芝加哥分校4德国图宾根...
黑色2奥特马尔Hilliges11ETHZürich2马克斯·普朗克智能系统研究所,图宾根3马克斯普朗克ETH学习系统摘要传统的3D可变形人脸模型(3DMM)提供了对表情的细粒度控制,但不能容易地捕捉几何和外观细节。神经体积表示...
4191从穿着衣服的3D扫描序列Chao Zhang1,2,Sergi Pujades1,Michael Black1,and Gerard Pons-Moll11MPIforIntelligentSystems,Tubingen,German y2部英国约克大学计算机科学系图1:给定静态3D扫描或3D扫描序列...
推荐文章
- python入门(13)异常与文件_except filenotfounderror:-程序员宅基地
- Android面试攻略_详细了解在当今的社会里android工程师应具备什么的技能?并能详细说说自己的见解。-程序员宅基地
- Zendframework 1.6整合Smarty_setting private or protected class member is not a-程序员宅基地
- Qt-装饰者模式_qt装饰模式-程序员宅基地
- 新开普掌上校园服务管理平台service.action RCE漏洞复现 [附POC]-程序员宅基地
- 基于 Milvus 的音频检索系统-程序员宅基地
- 331、基于51单片机智能红外遥控暖风机温度无线蓝牙远程控制系统设计(程序+原理图+配套资料等)_红外感应暖风机自动控制系统设计-程序员宅基地
- Android自定义圆角矩形图片ImageView_android 矩形圆角imageview-程序员宅基地
- 又见回文 字符串-程序员宅基地
- switch的参数可以是什么类型?_switch的参数有哪些-程序员宅基地